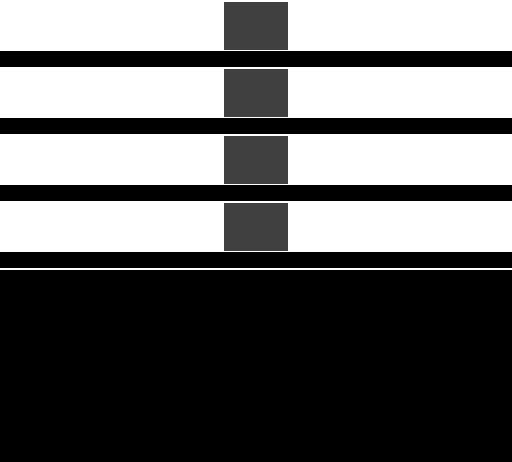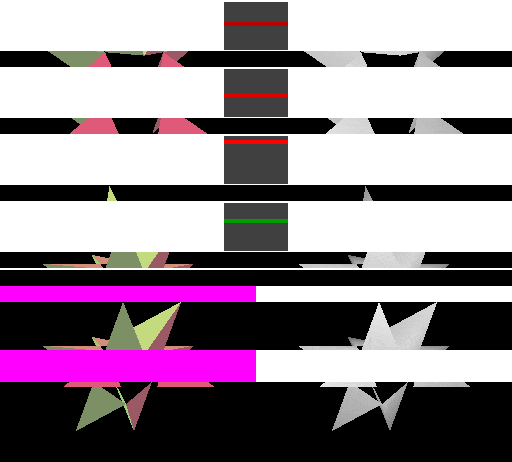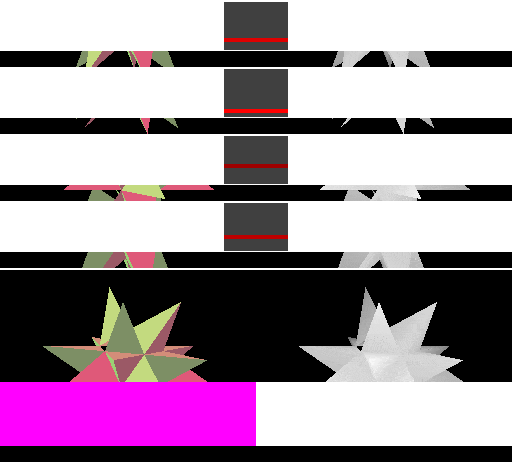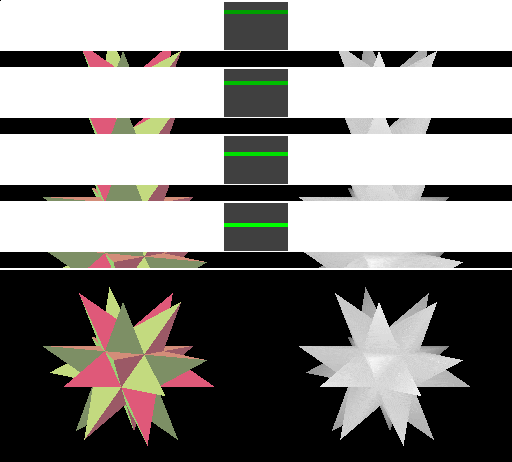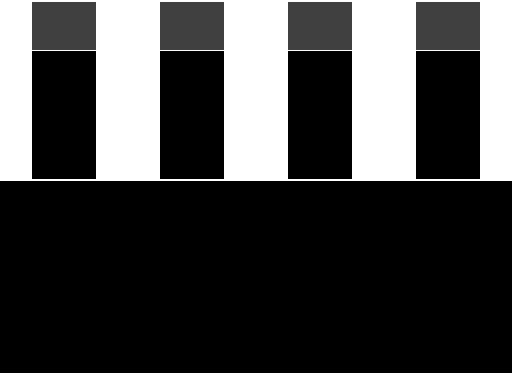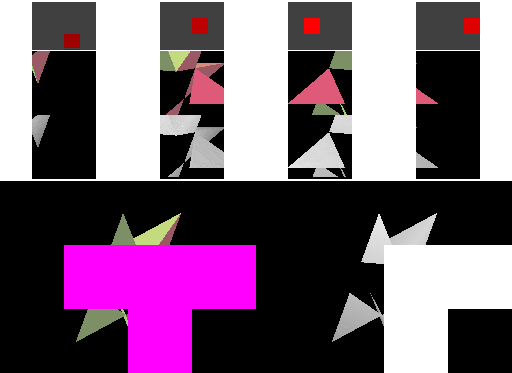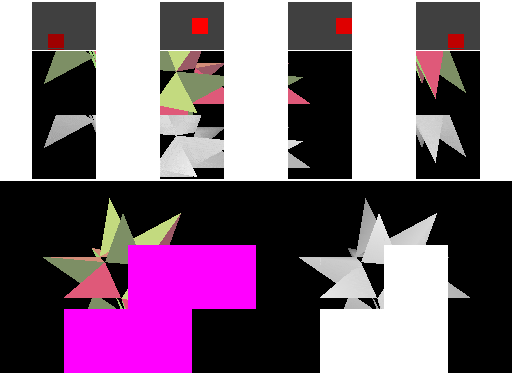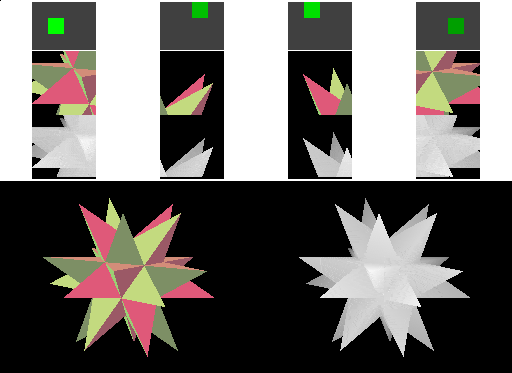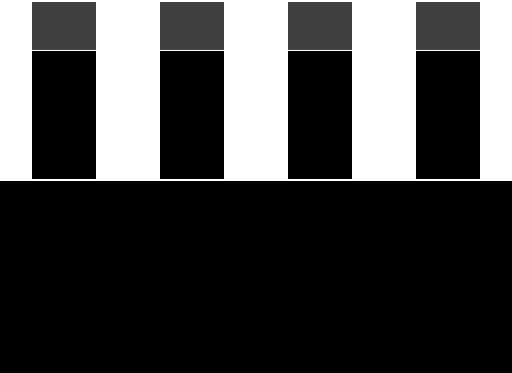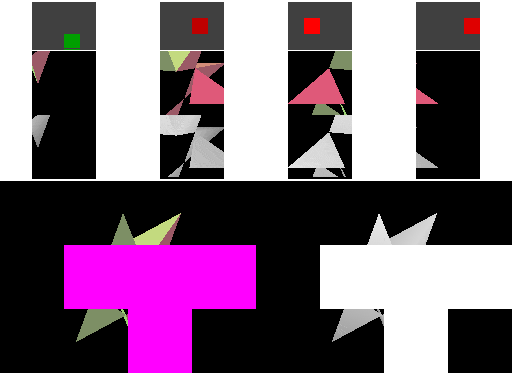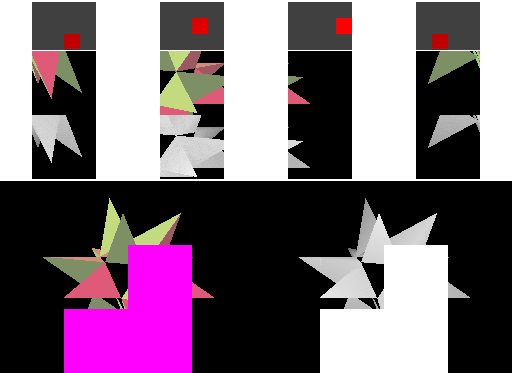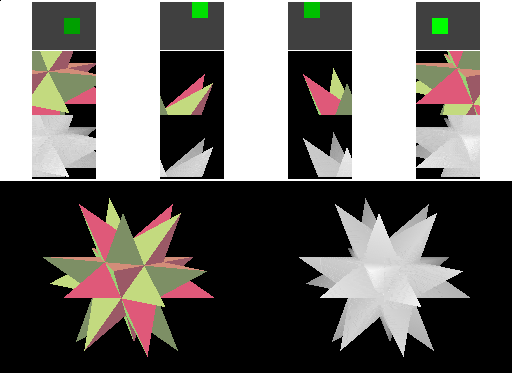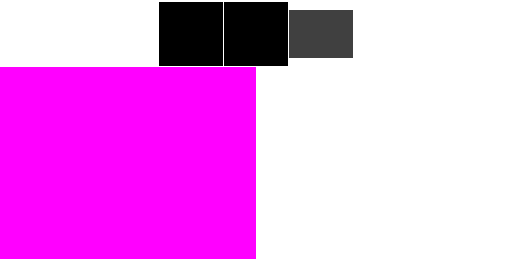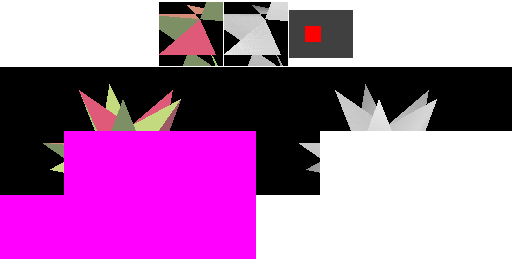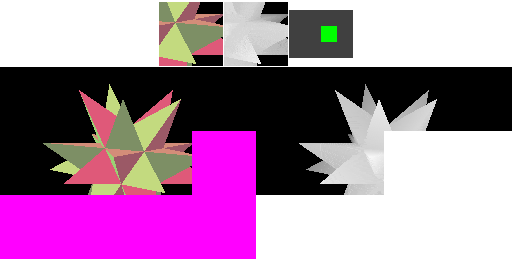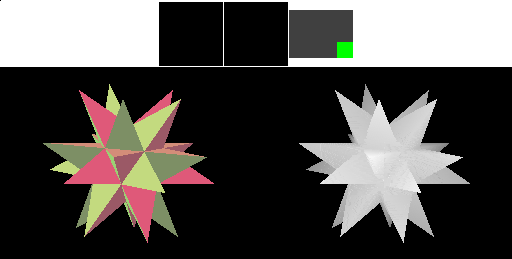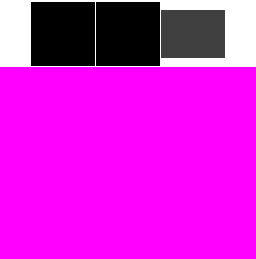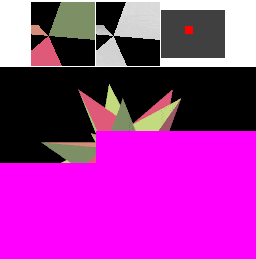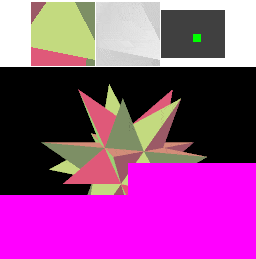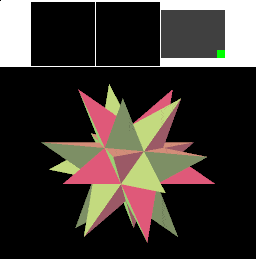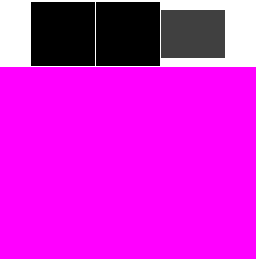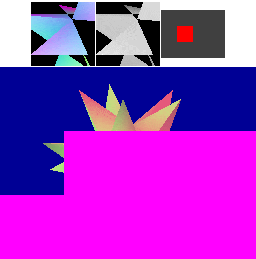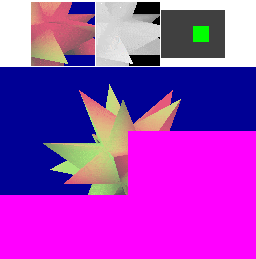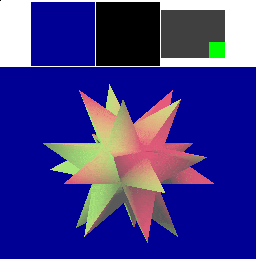Modern graphics hardware requires a high amount of memory bandwidth as part of rendering operations. External memory bandwidth is costly in terms of space and power requirements, especially for mobile rendering. This article discusses tile-based rendering, the approach used by most mobile graphics hardware - and, increasingly, by desktop hardware.
Please note: This article contains a number of animations. Click on the button below an image to activate its animation.
Immediate mode rasterizers
The traditional interface presented by a graphics API is that of submitting triangles in order, with the concept that the GPU renders each triangle in turn. That is, rasterization happens as shown below:
These images, like others below, show the color framebuffer on the left and the corresponding depth buffer on the right.
Hardware which processes triangles immediately as they are submitted, as shown here, is known as an Immediate-Mode Renderer ("IMR"). Historically, desktop and console GPUs have behaved in roughly this way.
In an IMR, the graphics pipeline proceeds top-to-bottom for each primitive, accessing memory on a per-primitive basis.
Memory use in an Immediate-Mode Renderer
A naïve implementation of an immediate-mode renderer might use a large amount of memory bandwidth. The next diagram shows that a large amount of memory is transferred during rasterization even with a simple cache for the framebuffer pixels and depth values. IMRs cause memory to be accessed in an unpredictable order, determined by the way triangles are submitted.
In this diagram, four "cache lines" of consecutive image memory are shown above the image as it is rendered. Above each cache line is a miniature rectangle showing where the pixels corresponding to the cache line fall in the framebuffer: red for "dirty" cache lines that have been written to, green for "clean" cache lines that still match memory, and brighter colors for cache lines that have been accessed more recently. Framebuffer pixels corresponding to "dirty" cache lines are shown in magenta (framebuffer) and white (depth buffer).
Tiled memory
The first step towards reducing memory bandwidth is to treat each cache line as covering a two-dimensional rectangular area (a "tile") in memory. Triangles that are near to each other in space are often submitted near each other in time (in this example, each "spike" of the object is drawn before moving on to the next), so better grouping of the cache area results in more cache hits. With square cache areas that are the same size as a linear cache, more rendering happens within the cache, and transfers to memory are less frequent - we've reduced external memory bandwidth! A similar technique is often used in texture storage, since the reading of texture values similarly shows spatial locality of reference.
This example is simplified - actual hardware may use more complex mappings between pixels and memory in order to further improve locality of reference.
This time the four cache lines (spaced out horizontally) each cover a square area in the framebuffer and depth buffer. The cached framebuffer area is now shown above the corresponding cached depth buffer area. The cache lines hold the same number of pixels as for the linear cache in the previous example.
Rasterizing within tiles
In a real-world situation, the framebuffer would likely be larger relative to the cached tiles. One problem with the technique we've shown so far is that a large triangle might thrash the cache if drawn in simple top-to-bottom order, since each horizontal line on the screen might cover more tiles than can fit in the cache. We can solve this problem by changing the order in which the pixels within a triangle are rasterized: we can draw all the pixels that the triangle covers within one tile before moving on to the next tile.
Since in our simple example the cache can cover the entire framebuffer width, this approach doesn't reduce the number of memory transfers that are performed. However, we can see the difference - rendering for a triangle completes in one cached tile before moving to the next.
Note: This animation takes longer than the last one because the image is updated after each tile has processed a triangle; the previous animation updated only after each triangle was completely rendered and during transfers between tiles an memory. In real hardware, performance would be the same - and, if the previous approach caused the cache to thrash, the performance of this version would be better.
We would get even better memory access if, rather than just processing all the pixels corresponding to one triangle before moving on to the next tile, we processed the pixels for all the triangles in the scene. This is the optimization performed by tile-based renderers (or "TBRs").
Binning
The first step of tile-based rendering is to determine which triangles affect each tile. A primitive implementation of a tile-based renderer could simply render the entire scene for each tile, clipped to the area covered by the cache. In practice, with large framebuffers and relatively small tiles, this would be very inefficient. Instead, when geometry is submitted for rendering, rather than being immediately rasterized, it is "binned" to a structure in memory that determines which tiles it could affect. Note that this process involves vertex shading, since this affects the location of triangles, but not fragment shading.
This diagram shows each triangle of our scene being "binned" into twelve tiles that cover the frame buffer in a 4x3 pattern. The "framebuffer" at the bottom shows the triangle as it is submitted. Above the full-size framebuffer is a 4x3 arrangement of miniature framebuffers, each showing only the triangles that have been "binned" into the corresponding rectangular tile of the image; the area corresponding to the tile is faintly outlined.
Tile-based rasterization
Once the geometry has been sorted into bins, the rasterizer can process the scene one bin at a time, writing only to local tile memory until processing of the tile is finished. Since each tile is processed only once, the "cache" is now reduced to a single tile. This in-order processing includes clearing the framebuffer - all of the framebuffer is "dirty" until the tile is processed.
Rendering has now been broken into two stages: binning, which writes to memory, then rasterization, that reads the bin contents. The intermediate store of geometry is typically small relative to the framebuffer, and is accessed in an ordered way.
Because the rasterization of tiles cannot begin until all the geometry has been processed, tile-based rendering introduces latency compared with immediate-mode rendering. In return, the reduction in bandwidth increases the rasterization speed. In some tile-based rendering hardware, the binning and rasterizing operations are pipelined. Therefore any operation that limits this parallelism (such as a vertex shader that depends on the previous frame's output, or a texture which is modified frame-by-frame and is not double-buffered) introduces a "bubble" that reduces performance. Additionally some tile-based rendering hardware is limited in the amount of geometry which can be processed in the binning pass.
Nonetheless, the bandwidth reduction of tile-based rendering means that almost all mobile hardware is based on tiling. Even traditional desktop IMR vendors are moving towards a partly tiled approach with their latest hardware. This means that both desktop and mobile platforms can benefit from API changes designed to support tillers (such as Vulkan Subpasses).
Since we process all the geometry contributing to the image one tile at a time, it may not be necessary to read any previous value from the framebuffer - we can clear the image as part of the tile processing (as shown above) and avoid the bandwidth cost of a read unless we really need previous contents. It is often also possible to avoid writing the depth buffer to memory (not shown in the above example), since typically the depth value is only used during rendering and does not need to persist between frames.
External traffic to the framebuffer is now limited to one write per tile - although these writes include clearing the framebuffer to a background color when no other primitives were there.
Multisampling
Tile-based rendering also provides a low-bandwidth way to implement antialiasing: we can render to the tiles normally, and average pixel values as part of the operation of writing the tile memory. This downsampling step is known as "resolving" the tile buffer. When multisampling (as opposed to supersampling), not every on-chip pixel is shaded.
If the tile buffer is of a fixed size, antialiasing means the image must be divided into more tiles, and there are more writes from tile memory to the framebuffer - but the total amount of memory transferred to the framebuffer is unaffected by the degree of multisampling. The full-resolution version of the framebuffer (the version that has not been downsampled) never needs to be written to memory, so long as no further processing is done to the same render target. This can save a lot of bandwidth, and for simple scenes makes multisampling almost free.
In this animation, 2x2 antialiasing has made the tile coverage in the framebuffer smaller, so more passes are needed. The geometry rasterized in the tile memory is double-sized, and shrunk when written to the framebuffer. The depth buffer is only needed on-chip, not in main memory, so only the color aspect of the full framebuffer is shown - the on-chip depth value is discarded once the tile is processed.
Traditional deferred shading
It is not normally possible to read from the framebuffer attachment during the process of rendering to it. Nonetheless, some techniques rely on being able to read back the result of previous rendering operations.
One such technique is "deferred rendering": only basic information is recorded as each primitive is rasterized, then a second pass is made over the rendered scene, using this recorded information as input to the shading operations per pixel. Deferred rendering can reduce the number of required costly state changes, and increase the potential parallelism available to fragment shaders.
A simple implementation of deferred rendering has a high bandwidth cost, since the entire framebuffer, including all per-pixel values, must be read and written for the deferred shading pass.
This example shows the cache behavior in a simple deferred shading implementation. The first pass simply records the Phong-interpolated surface normal. The second pass reads this information for every pixel in the image and uses the interpolated normal for lighting calculations - reading and writing every image line in the process.
Tiling and deferred shading
Because deferred shading (and the related deferred lighting approach) require only the contents of the current pixel to be read, the scene can still be processed one tile at a time. Only the final result of the shading pass needs to be written to the framebuffer.
To achieve this in Vulkan, the entire sequence of rendering is treated as a single render pass, and the geometry and shading operations are each contained in a subpass. In OpenGL ES, a similar approach is possible less formally with Pixel Local Storage. With these approaches, the memory access cost of deferred shading is no greater than for simple rendering - and there is still no need to write the depth buffer.
This example shows deferred shading in a tile-based renderer: the triangle rasterisation and the subsequent shading pass proceed within the tile memory, with only the RGB shading result being written out to the framebuffer.
Advantages of tile-based rendering
Frame buffer memory bandwidth is greatly reduced, reducing power and increasing speed.
Mobile memory is typically slower and lower power than desktop systems, and bandwidth is shared with the CPU, so access is very costly.
With API support, off-chip memory requirements may also be reduced (it may not be necessary to allocate an off-chip Z buffer at all, for example).
Texture cache performance can be improved (textures covering multiple primitives may be accessed more coherently one tile at a time than one primitive at a time.
Much less on-chip space is needed for good performance compared with a general-purpose frame buffer cache.
This means that more space can be dedicated to texture cache, further reducing bandwidth.
Limitations of tile-based rendering
While there are many performance advantages to tile-based rendering, there are some restrictions imposed by the technique:
The two-stage binning and fragment passes introduce latency
This latency should be hidden by pipelining and improved performance, but makes some operations relatively more costly
In pipelined tiled rendering, framebuffer and textures required for rendering should be double-buffered so as to avoid stalling the pipeline
Framebuffer reads that might fall outside the current fragment are relatively more costly
Operations such as screen-space ray tracing require writing all the framebuffer data - removing the ability to discard full-resolution images and depth values after use
There is a cost to traversing the geometry repeatedly
Scenes that are vertex-shader bound may have increased overhead in a tiler
The binning pass may have limitations
Some implementations may run out of space for binning primitives in very complex scenes, or may have optimizations that are bypassed by unusual input (such as highly irregular geometry)
Switching to a different render target and back involves flushing all working data to memory and later reading it back
For a tiler, it is especially important that shadow and environment maps be generated before the main frame buffer, not "on demand" during final rendering (though this is good advice for most GPUs)
Graphics state (such as shaders) may change more frequently and less predictably
Geometry that is "skipped" means that states do not necessarily follow in turn, making incremental state updates hard to implement
In most cases, the behavior of a tile-based GPU should not be appreciably worse than for an immediate-mode renderer using similarly limited hardware (indeed, some hardware can choose whether or not to run in a tiled mode), but it is possible to remove the performance benefits of tile-based rendering with the wrong use pattern.
Summary
Tile-based rendering is a technique used by modern GPUs to reduce the bandwidth requirements of accessing off-chip framebuffer memory. Almost ubiquitous in the mobile space where external memory access is costly and rendering demands have historically been lower, desktop GPUs are now beginning to make use of partially-tile-based rendering as well.
Vulkan has specific features intended to make the best use of tile-based renderers, including control over whether to load or clear previous framebuffer content, whether to discard or write attachment contents and control over attachment resolving, and subpasses. OpenGL ES can achieve similar behavior with extensions, but these are not universally supported. To get the best performance from current and future GPUs, it is important to make proper use of the API so that tile-based rendering can proceed efficiently.
Manage Your Cookies
We use cookies to improve your experience on our website and to show you relevant
advertising. Manage you settings for our cookies below.
Essential Cookies
These cookies are essential as they enable you to move around the website. This
category cannot be disabled.
Company
Domain
Samsung Electronics
developer.samsung.com, .samsung.com
Analytical/Performance Cookies
These cookies collect information about how you use our website. for example which
pages you visit most often. All information these cookies collect is used to improve
how the website works.
Company
Domain
Samsung Electronics
.samsung.com
Functionality Cookies
These cookies allow our website to remember choices you make (such as your user name, language or the region your are in) and
tailor the website to provide enhanced features and content for you.
Company
Domain
Samsung Electronics
developer.samsung.com, google.account.samsung.com
Preferences Submitted
You have successfully updated your cookie preferences.